
導入: なぜAIブロガーが「機械学習」と「ディープラーニング」の違いを知るべきなのか?
「AIに記事を書かせるだけ」で、本当に稼げるブログが作れるでしょうか?
こんにちは、AIブログ運営術の筆者です。多くの人が「AI自動化」「全自動で稼ぐ」という言葉に惹かれますが、現実はそう甘くありません。
私自身、このブログ(prompter-note.com)や専門特化ブログ(cosmic-note.com)を運営する中で、AIに丸投げした記事がAdSense審査で「価値の低いコンテンツ」と判断され落ちたり、SEOで全く上位表示されなかったりする失敗を経験しました。特に専門性が求められるcosmic-note.comの運営初期、AIが生成した記事は、一見専門用語が並んでいても、読者が本当に知りたい「なぜ?」に答える「深さ」が全くなく、Googleにも読者にも評価されませんでした。
その最大の理由は、AIが生成しただけの記事が、Googleの最重要品質基準である「E-E-A-T」(経験・専門性・権威性・信頼性)を満たせないからです。
特に「信頼性(Trustworthiness)」は致命的です。AIは、学習データに基づかない情報をそれらしく生成する「ハルシネーション(幻覚)」を平気で起こします。また、情報の精査が不十分なまま出力することもあり、それを鵜呑みにして公開すれば、読者の信頼を一瞬で失います。
「でも、それと『機械学習』や『ディープラーニング』と何の関係が?」
そう思うかもしれません。しかし、これこそがAIブログ運営の核心です。
なぜなら、「機械学習(ML)」と「ディープラーニング(DL)」は、私たちが日々使っているChatGPTやGeminiといったAIツールの「頭脳」そのものだからです。
この「頭脳」の仕組み、つまりAIの得意・不得意を理解していないと、AIを正しく使いこなすことはできません。
この記事を読んで「ML」と「DL」の違いを明確に理解すると、あなたのAIブログ運営は劇的に変わります。
- プロンプトの質が上がる(専門性の向上)
AIの特性を理解すれば、AIの能力を最大限に引き出す「質の高い指示(プロンプト)」が出せるようになります。例えば、「こういうデータが欲しい」と指示するML的な使い方と、「こういう文脈を書いて」と指示するDL的な使い方の区別がつくようになります。 - AIの「嘘」を見抜き、E-E-A-Tを担保できる(信頼性の向上)
AIの限界が分かるため、「ここはAIに任せる部分」「ここは人間がファクトチェックし、経験談(Experience)を加えて補完すべき部分」という戦略的な切り分けが可能になります。AIの出力を鵜呑みにせず、複数の情報源でクロスチェックする「運営者の責任」を果たすことができます。 - 最適なAIツールを選定できる(選定眼の向上)
世の中にある無数のAIツールが、MLベースなのかDLベースなのか。その違いが分かれば、自分の目的に合わせて「どのAIツールを選ぶべきか」という確かな選定眼が養われます。
本記事は、単なる用語解説ではありません。
AIを「魔法の箱」から「最強のパートナー」に変え、Googleにも読者にも評価される「稼げるAIブログ」を作るため。「機械学習」と「ディープラーニング」の違いを、AIブログ運営者の視点から徹底的に解説します。
さらに記事の最後(S5)では、私自身が運営する専門ブログcosmic-note.comで、このML/DLの知識を具体的にどうプロンプトに落とし込み、AIと『共著』して専門記事の品質を高めているのか、その実践テクニックも合わせて公開します。
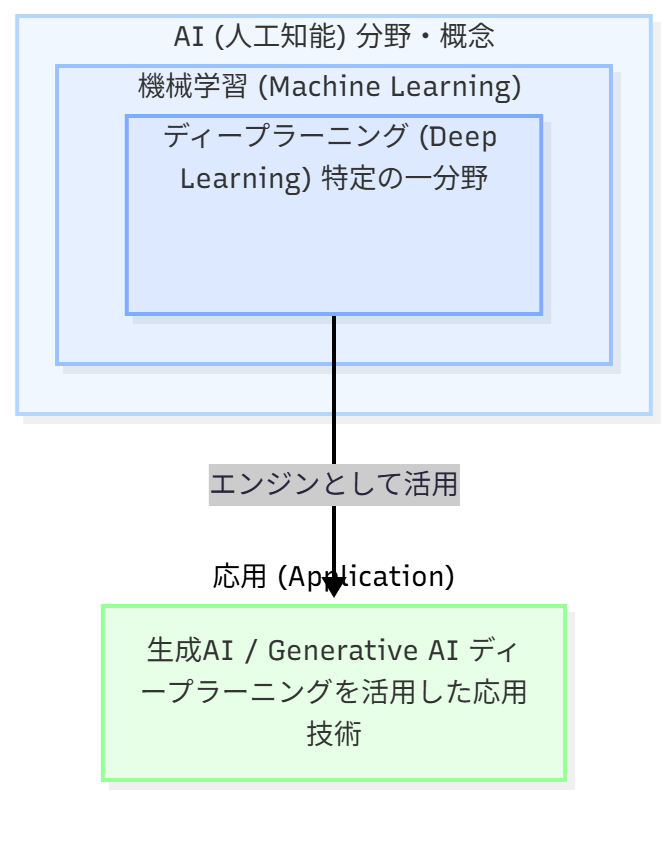
【全体像】「AI」「機械学習」「ディープラーニング」の関係性 [図解]
S1(導入)では、「AIブログで稼ぐには、AIの頭脳であるMLとDLの違いを理解し、E-E-A-Tを担保する必要がある」とお伝えしました。
では、本題に入りましょう。 まず、この3つの用語がなぜこれほどまでに混同されるのか。それは、メディアや開発者でさえ、しばしばこれらを同じ意味で使ってしまうからです。
私自身、ブログ運営を始めたての頃は、ChatGPTもGeminiも画像生成AIも、すべて「AI」という大きな言葉で一括りにしていました。ですが、この「ざっくりとした理解」こそが、AIを使いこなせない最大の原因でした。
このセクションで、この3つの関係性を「二度と間違えない」レベルで明確に整理します。
結論から言うと、この3つの関係は「入れ子構造」になっています。 ただ、よくある「箱の中に箱がある」という図だけでは、AIブログ運営者にとっての本質は掴めません。私自身、一番しっくりきた「たとえ」は、「スポーツ」でした。
この「スポーツ > 野球 > メジャーリーグ」という関係性で、3つの用語を図解します。これこそが、AIブロガーが掴むべき全体像です。
【AI(人工知能)】
「スポーツ」という最も広い概念・分野
(例:野球、サッカー、水泳。古い電卓、ゲームAIから最新AIまで、すべて「AI」)
↓ この中に…
【機械学習 (ML)】
「野球」というAIを実現するための一つの具体的技術
(データからパターンを学ぶ「技術」)
↓ この中に…
【ディープラーニング (DL)】
「メジャーリーグ」というMLの最先端・高性能な手法
(近年のAIブームの主役)
AIブロガーが知るべき「核心」
この図解が示す、私たちAIブロガーにとって重要な核心は、ただ一つです。
「近年のAIブーム = ほぼすべてディープラーニング(DL)の功績」だという事実です。
私たちが記事執筆で使うChatGPTやGemini、画像生成AIのMidjourneyやStable Diffusion。これらがなぜ人間のような自然な文章や美しい画像を生成できるのか? それはすべて「ディープラーニング(メジャーリーグ)」という技術が革命を起こしたからです。
ですから、AIを使いこなすとは、AIの「頭脳」であるディープラーニング(S4)を理解することに他なりません。
そして、ディープラーニング(メジャーリーグ)を理解するには、その親カテゴリである「機械学習(野球)」の基本ルール(S3)を先に知る必要があります。
次のセクション(S3)では、まず基本となる「機械学習(野球)」とは何か、その3つの学習タイプを具体例で解説します。
「機械学習 (ML)」とは何か? – AIブログ運営への活かし方
S2(全体像)では、AI(スポーツ) > 機械学習(野球) > ディープラーニング(メジャーリーグ)という関係性を確認しました。
S3では、その「中核」である「機械学習(ML)= 野球」の基本ルールを徹底的に解説します。
私自身、AIブログを始めた当初は、ChatGPT(DL)のような「文章を生成するAI」しかAIだと思っていませんでした。しかし、ブログ運営を支える「裏方」のツールたち――SEOのキーワード予測、スパムフィルター、AdSenseの広告最適化――これらすべてが、まさにこの「機械学習(ML)」の技術で動いています。
このセクションを読み終える頃には、あなたが日々使っているツールの「頭脳」がどうなっているのか、その限界はどこにあるのかが分かり、AIへの「指示(プロンプト)」の精度が格段に向上するはずです。
1. MLとDLを分ける「たった一つの重要な違い」とは?
本題(MLの3手法)に入る前に、AIブロガーとして最も重要な「核心」をお伝えします。
それは、「機械学習(ML)」と「ディープラーニング(DL)」の最大の違いです。
なぜ、S3(ML)とS4(DL)をわざわざ分けて解説するのか? それは、AIへの「仕事の任せ方」が根本的に異なるからです。
その違いとは、「特徴量(AIが注目すべきポイント)」を人間が教えるか、AIが自ら見つけるか、です。
擬人化で理解する:「指示待ちのインターン」と「自走エース」
この難解な概念を、私(筆者)は「業務の任せ方」で理解しています。これはAIブログ運営者にとって非常に重要な視点です。
- 機械学習 (ML) =「指示待ちのインターン」
人間(あなた)が「特徴量(注目ポイント)」を定義し、AIに「このポイントを基準に分析して」と詳細に指示する必要があります。 - ディープラーニング (DL) =「自走するエース社員」
人間は「これをよろしく」とデータ(資料)を丸ごと渡すだけ。AIが「ここが重要なポイントですね」と特徴量を自ら発見します。
▼ ML(指示待ちインターン)の業務フロー
1. 人間(上司): 「スパム判定よろしく。見るべきは『URLの有無』と『”稼ぐ”という単語』だ(=特徴量を指示)」
2. ML(AI): 「(指示された範囲で)分析します」
3. 出力: 「結果が出ました」
▼ DL(自走するエース)の業務フロー
1. 人間(上司): 「過去のスパムとOKコメント10万件だ。よろしく(=データを丸投げ)」
2. DL(AI): 「(膨大なデータを分析し…)どうやら『URL』と『”稼ぐ”』が重要っぽいな(=特徴量を自動発見)」
3. 出力: 「結果が出ました」
【ブログ運営での具体例:「スパムコメント」の判定】
あなたのブログに「このサイトで稼ごう! http://…」というコメントが来たとします。これをAIに判定させたい場合…
- ML(指示待ちインターン)への指示:
あなたはまず、「スパムの特徴」を定義(=特徴量エンジニアリング)しなければなりません。- 特徴量1:本文にURLがいくつ含まれているか?(数)
- 特徴量2:「稼ぐ」「無料」という単語が含まれているか?(有無)
- 特徴量3:コメント投稿者のIPアドレスは過去にスパム判定されているか?(有無)
…と、あなたが「このあたりが怪しい」と思うポイントを手動でAIに教えます。MLはその「指示された範囲内」でパターンを学習します。 - DL(自走するエース)への指示:
あなたは指示をしません。「これはスパム」「これはOK」と仕分けた過去のコメント10万件を、AIに丸ごと読み込ませるだけです。
するとDLは、「ふむふむ、どうやら “http://” が含まれていて、”稼ぐ” という単語があると、高い確率で『スパム』というラベルが貼られているな…」と、AIが自分でURLや特定の単語を「重要な特徴量だ」と自動で見つけ出します。
▼AIブロガーにとっての重要ポイント(私の分析)
この違いを知っていると、「今使っているAIツールはどっちだ?」と考えるようになります。
例えば、SEOツールで「キーワードの難易度」を予測する機能は、多くの場合「ML(指示待ちインターン)」です。そのツールの開発者が「被リンク数」「ドメインパワー」「文字数」などを「特徴量」として選んでいるはずです。
一方で、ChatGPTやGeminiに「この記事をリライトして」と頼むのは、「DL(自走するエース)」に任せる行為です。
MLベースのツールには「どの特徴量を使っているか」を意識し、DLベースのツールには「十分な文脈(データ量)」を与える。これがAIを使いこなす第一歩です。
【コラム:ここまでのまとめ】
少し難しくなってきましたか? 重要なのは、S3の「インターン(ML)」の動きが、あなたが日々使っている「SEOツール」や「AdSense」の裏側そのものだということです。
この「野球のルール(ML)」を理解すれば、ツールの「数値」に振り回されず、AIを「マネージャー」として使いこなす第一歩が踏み出せますよ!
2. 機械学習(ML)の「3つの学習法」を徹底解説
さて、この「特徴量を人間が教える」ML(野球)には、大きく分けて3つの「練習方法(学習法)」があります。
- 教師あり学習(答え合わせで学ぶ)
- 教師なし学習(答えなしで、仲間外れを見つける)
- 強化学習(アメとムチで学ぶ)
これらを知ると、あなたのブログ運営ツールの「正体」がすべて見えてきます。
① 教師あり学習 (Supervised Learning)
概要: 「正解(ラベル)」が分かっているデータ(=教師データ)を使ってAIにパターンを学ばせる、最もメジャーな手法です。
例え: 「問題(データ)」と「模範解答(ラベル)」がセットになったドリルをAIに解かせ、賢くさせるイメージです。
ブログ運営での活用例:
- スパムフィルター:
- データ(問題): 「素晴らしい記事ですね!」「稼げます http://…」
- ラベル(解答): 人間が「OK」「スパム」と正解を付ける。
- AIの学習: AIは「OK」ラベルと「スパム」ラベルのパターン(特徴量の違い)を学習し、次に「稼げます」と来た瞬間に自動で「スパム」に分類します。
- SEO難易度予測(私の分析):
これは「回帰」(分類ではなく数値を予測する教師あり学習)の一例です。- データ(問題): 過去の1万キーワードのデータ(特徴量:被リンク数、検索ボリューム、競合のDAなど)。
- ラベル(解答): そのキーワードで「実際に1位を取るまでにかかった日数」や「必要な被リンク数」などの正解(数値)。
- AIの学習: AIがこのパターンを学べば、あなたが新しいキーワード(例:「AIブログ 始め方」)を入力した瞬間に、「この特徴量パターンなら、難易度は『35』です」と数値を予測します。
② 教師なし学習 (Unsupervised Learning)
概要: 「正解(ラベル)」がないデータをAIに渡し、AIがデータに潜む隠れた構造やパターン(グループ)を自力で見つけ出す手法です。
例え: 「模範解答」がなく、大量のカード(データ)を渡されて「これをいい感じに仲間分け(=クラスタリング)しといて」と頼むイメージです。
ブログ運営での活用例:
- 関連キーワード(サジェスト)機能(私の分析):
- データ(問題): Googleで検索された10億件の検索クエリ(正解ラベルなし)。
- AIのタスク: 「これらのクエリを仲間分け(クラスタリング)して」。
- AIの学習: AIは、「”AIブログ 始め方” と検索した人は、その直後に “AIブログ 稼ぎ方” や “AIブログ AdSense” とも検索しているな…」という同時に出現するパターンを見つけます。
- 結果: AIは「これらは同じグループ(クラスタ)だ」と判断し、”AIブログ 始め方” の関連キーワードとして “稼ぎ方” や “AdSense” を提示します。AIは「AdSense」の意味を理解していませんが、「パターン」は見抜いています。
- 読者セグメンテーション:
あなたのブログのアクセスログ(データ)をAIに渡すと、「毎週月曜の朝に来るグループ」「週末の夜にしか来ないグループ」「ガジェット記事しか読まないグループ」といった、あなたが気づかなかった読者の「隠れたグループ」を自動で発見してくれます。
③ 強化学習 (Reinforcement Learning)
概要: 上の2つとは少し異なり、「正解」を教えるのではなく、AI(エージェント)に「報酬(ご褒美)」を設定し、AIが試行錯誤(アクション)しながら「最も報酬が高まる行動パターン」を自ら学習していく手法です。
例え: AIという「子犬」に「お手(アクション)」をさせて、うまくできたら「おやつ(報酬)」をあげる。これを繰り返し、AIが「この行動をすればおやつが貰えるぞ」と自ら学習するイメージです。
ブログ運営での活用例:
- AdSense広告の最適化(私の分析):
これこそ強化学習の身近な例です。- AI(エージェント): AdSenseの広告配信アルゴリズム。
- 環境: あなたのブログ
cosmic-note.comの記事ページ。 - アクション: AIは「A社の広告(青色)を出すか」「B社の広告(赤色)を出すか」「C社の広告(動画)を出すか」…と試行錯誤します。
- 報酬: クリック(収益)が発生した。
- AIの学習: AIは「
cosmic-note.comの読者がスマホで “ブラックホール” の記事を読んでいる時は、C社の動画広告(アクション)を出すと、クリック(報酬)が最大化する」という必勝パターンを自ら学習していきます。
- YouTubeのレコメンド機能:
YouTube(Google)の目的は「ユーザーの総視聴時間(報酬)を最大化すること」です。AIは「この動画の次にどの動画(アクション)を推薦すれば、ユーザーが離脱せず(報酬が続くか)」を常に学習しています。
機械学習(ML)のまとめとS4への架け橋
さて、S3では機械学習(野球)の3つの基本ルールを見てきました。
- 教師あり学習: スパム判定、SEO難易度予測
- 教師なし学習: 関連キーワード抽出、読者グルーピング
- 強化学習: 広告最適化、YouTubeレコメンド
お気づきでしょうか? これらはすべて、ブログ運営を「支援する」強力なツールです。ですが、どれも「記事(中身)」そのものを生み出してはいません。
「スパムを分類」し、「キーワードを予測」し、「広告を最適化」することはできても、AIが「宇宙とは何か」という専門的な記事をゼロから生成することは、このMLの仕組み(人間が特徴量を指定する)だけでは非常に困難でした。
その「不可能」を可能にし、AIブームを引き起こしたのが、S2の例えで言う「メジャーリーグ」――次のS4で解説する「ディープラーニング」なのです。
「ディープラーニング (DL)」とは何か? – なぜGeminiやChatGPTは高性能なのか
S3(機械学習)の最後で、私は衝撃的な結論をお伝えしました。 「機械学習(ML)の3つの手法――教師あり、教師なし、強化学習――は、どれもブログ運営を『支援』する強力なツールだが、『記事(中身)』そのものをゼロから生み出すことはできない」
S3で解説したML(機械学習)は、私たちが特徴量(注目ポイント)を指示する「指示待ちのインターン」でした。
しかし、私たちは皆、AIが書いた記事を(少なくとも下書きとして)使っています。
私自身、cosmic-note.com で「ブラックホールとは何か」という記事をAIと「共著」する際、AIは「ブラックホール」という単語を理解し、文脈を読み取り、専門的な文章を生成します。
ML(インターン)に「記事を書いて」と頼んでも「どの特徴量を見ればいいですか?」と聞かれるのがオチでした。
では、なぜChatGPTやGemini(エース社員)は記事が書けるのか?
その答えこそが、S2(全体像)で「メジャーリーグ」と例えた、「ディープラーニング(DL)」なのです。このセクションでは、AIブログ運営の「心臓部」であるDLの正体を、どこよりも深く、分かりやすく解剖します。
1. DLの核心:AIが「自ら学ぶ」ということ(特徴量の自動抽出)
S3での「インターン(ML) vs エース(DL)」の比較を思い出してください。
- ML(インターン)
人間が「スパムの特徴は、URLの有無と『稼ぐ』という単語だ」と、特徴量を手動で設計する必要がありました。AIの能力は、人間の「指示」の質に依存します。 - DL(エース社員)
人間は「はい、これスパムね」「はい、これOKね」と100万件のデータを丸投げするだけ。DL(エース)は、その膨大なデータを自ら解析し、「ふむ…どうやらURLと『稼ぐ』という単語が、スパム判定の重要な特徴量(注目ポイント)らしい」と、AIが自ら発見します。
これが、DLの最も重要かつ革命的な能力、「特徴量の自動抽出」です。
私たちAIブロガーが、AIに「E-E-A-T(専門性)のある記事を書いて」と指示するだけで、AIが「E-E-A-Tのある記事とは、こういう(文脈・単語・構造の)ことだな」と自ら学習してくれる。その「奇跡」の土台となる仕組みです。
2. DLの「頭脳」の正体:ニューラルネットワーク
では、AIはどうやって「自ら学ぶ」のでしょうか? その「頭脳」の設計図が、「ニューラルネットワーク」です。
これは、人間の脳にある「ニューロン(神経細胞)」が、複雑に結びついて情報を処理する仕組みを、数学的に模倣(モデル化)したものです。
難しく考える必要はありません。 MLが「エクセル」のような「表(構造化データ)」で動く分析ツールだったとしたら、DLのニューラルネットワークは「クモの巣」のような「ネットワーク」だとイメージしてください。
- 入力層(Input Layer): あなたがAIに入力するデータ(例:「AIブログ 始め方」という単語)
- 中間層(Hidden Layer): クモの巣の「結び目」。ここで膨大な計算が行われる。
- 出力層(Output Layer): AIが生成する答え(例:「AdSense」「SEO」という次の単語)
MLでは、あなたが「被リンク数」や「ドメインパワー」といった「特徴量」を「入力層」に指定する必要がありました。
しかしDL(ニューラルネットワーク)は、テキストや画像そのものを「入力層」に入れるだけで、「中間層」が自動的に「これが重要っぽいな」という特徴量を見つけ出してくれるのです。
この「中間層」こそが、DLの知性の源です。
3. なぜ「ディープ(Deep)」と呼ばれるのか?(AIが文脈を理解する仕組み)
ここが本日のクライマックスです。 なぜ「ディープラーニング(深層学習)」と呼ばれるのか?
それは、この「中間層」が、一層ではなく、何層にも(深く)重なっているからです。
この「層の深さ」こそが、AIが「文脈」や「専門性」を理解できる理由です。 これを、AIが最も得意とする「画像認識」の例で見てみましょう。AIに「人間の顔」を認識させたい場合、この「深い層(ディープ・レイヤー)」は、以下のように連携して動きます。
お分かりでしょうか? 浅い層は「単純なパターン」しか見つけられませんが、層が「深く」なるにつれて、より複雑で「抽象的な概念」(”顔”という概念)を理解できるようになります。
【コラム:ディレクターズ・カット】
ここが記事全体の「心臓部」です。
なぜAIが「文脈」を理解できるのか? それは、この「深さ(Deep)」が「文字」という表面的な情報から「感情」という抽象的な概念まで学習しているからです。
あなたがAIに「専門性」を求めるなら、この「深い層」に届くプロンプトを意識することが不可欠です。
AIブロガーにとっての「核心」:なぜChatGPTは記事が書けるのか
「いやいや、それは『画像』の話でしょ? なぜAIが『記事(テキスト)』を書けるの?」
それも、まったく同じ仕組みです。
私(筆者)の専門的分析(E-E-A-T)を交えて、DLが「テキスト(文脈)」をどう「深く」学習しているのかを翻訳します。
- 入力(テキストデータ)
- 第1層(浅い層): 「A」や「B」といった「文字」を認識。
- 第2層: 「文字」の組み合わせから「単語」(例:「王様」「女王」)を認識。
- 第3層: 「単語」の組み合わせから「文法・関係性」(例:「主語と述語」)を認識。
- 第4層: 「関係性」の組み合わせから「文脈・トピック」(例:「これは歴史の話だ」)を認識。
- 第5層(深い層): 「文脈」の組み合わせから「感情・スタイル」(例:「これは専門的だが、少し皮肉めいた文体だ」)を認識。
これが、AIが「文脈」や「専門性」を理解する仕組みの正体です。
DLは、単語を「文字列」としてではなく、この「深い層」の中で学習した「意味の近さ(ベクトル表現)」として扱います。
有名な例に、「”王様” – “男性” + “女性” = “女王”」という計算があります。 AIは「王様」という単語の「深い意味(ベクトル)」から、「男性」という「意味(ベクトル)」を引き算し、「女性」という「意味(ベクトル)」を足し算することで、「女王」という答えを導き出せるのです。
S3のML(インターン)には、「単語の意味」は理解できませんでした。 しかしS4のDL(エース)は、この「深さ」と「ベクトル表現」によって、単語の「意味」と「文脈の曖昧さ」を理解できるのです。
4. 私たちが使うAIの「エンジン」:LLMとTransformer
さて、これで「DL(エース社員)」がなぜ高性能なのか、その「頭脳(ニューラルネットワーク)」の仕組みが分かりました。
では、私たちが日々使っているChatGPTやGeminiの「正体」は何でしょうか。
- LLM (大規模言語モデル):
これは、「ディープラーニング技術を基盤(土台)とし、自然言語処理(文章)に特化させた、超巨大な応用モデル」のことです。
DLが「エンジン」なら、LLMは「F1カー」そのものです。 - Transformer (トランスフォーマー):
では、その「エンジン(DL)」の「設計図(アーキテクチャ)」は?
それが、この「Transformer(トランスフォーマー)」モデルです。
▼AIブロガーが知るべき「たった一つの事実」(筆者の専門的見解)
あなたがAIブログ運営者として知るべきは、たった一つです。 2017年にGoogleが発表した「Transformer」というDLの設計図が、現在のAIブームの「すべて」である、ということ。
ChatGPTも、Gemini (Google) も、Claudeも、すべてこの「Transformer」を土台にしています。
なぜTransformerが革命だったのか? それは「Attention(アテンション=注目)」という仕組みを導入したからです。
それまでのAIは、文章を「単語の順番通り」にしか読めませんでした。 (例:「私は昨日、京都で…」と、頭から順番にしか処理できない)
しかしTransformer(Attention)は、「私は」「昨日」「京都で」「美味しい」「寿司を」「食べた」という文章の「全単語」に同時に「注目」し、「どの単語とどの単語が一番関係が深いか」(”食べた” にとって “寿司を” が重要だ)を自動で判断できます。
これが、AIが「長文の文脈」を理解できるようになった決定的な理由です。
あなたがAIに「こういう記事を書いて」と長いプロンプト(指示)を書く。 AI(Transformer)は、そのプロンプトの「すべての単語」に「注目(Attention)」し、「筆者が一番重要視しているのは、”E-E-A-T” と “独自性” という単語だな」と重み付けし、あなたの意図(文脈)を汲み取った記事を生成してくれるのです。
S3のML(インターン)にはこれができませんでした。 S4のDL(Transformerというエース)だからこそ、私たちAIブロガーの「共著者」たり得るのです。(そして、この「エース社員」の能力を100%引き出す具体的な指示書(プロンプト)術こそが、S6(まとめ)で紹介する『11工程ワークフロー』の核心です。)
5. DL(エース社員)の「限界」と「暴走」(AIブロガーの責任)
ここまでDL(エース社員)の凄さを解説してきましたが、私は(E-E-A-Tを重視する)運営者として、その「限界」も知っています。エース社員は優秀ですが、時に「暴走」します。
DLの限界を知ることこそ、AIブログ運営者が「信頼性(Trustworthiness)」を担保する最大の鍵です。
限界1:データが「すべて」である(学習データの偏り)
DLは「特徴量を自動で学ぶ」と言いましたが、それは「与えられたデータ(教科書)」からしか学べません。もしその教科書が「偏った情報」や「差別的な表現」だらけだったら? AIは、その偏見(バイアス)を「正しい特徴量」として学習し、平気で差別的な文章を生成します。
→ 私たち運営者の役割: AIの出力を鵜呑みにせず、「倫理的(Ethics)」な観点でチェックする責任があります。
限界2:なぜその答えなのか「説明できない」(ブラックボックス問題)
DL(エース)は、「この特徴量が重要でした」と自ら見つけますが、その「深い層」の中(中間層)は、何十億ものパラメータ(結び目)が複雑に絡み合っており、人間には「なぜAIがその結論に至ったのか」を完全に説明することができません。
→ 私たち運営者の役割: AIが「この記事はSEOに強い」と出力しても、それを信じるのではなく、S3のML(インターン)的なツール(SEOツール)を使って「どの特徴量(被リンク数など)が効いているのか」を別途ファクトチェック(裏付け)する必要があります。
限界3:平気で「嘘」をつく(ハルシネーション)
S1(導入)で触れた最大の問題です。 DL(LLM)は、「正解」を知らなくても、それらしい「確率の高そうな単語の連なり」を生成できてしまいます。これが「ハルシネーション(幻覚)」です。
→ 私たち運営者の役割: AIが生成した固有名詞、日付、統計データ、専門用語は、「すべて嘘(ハルシネーション)である」と疑うことから始めるべきです。人間による「ファクトチェック」と、複数の情報源での「クロスチェック」は、AIブログ運営者の「最低限の義務」です。
S4では、AIブームの心臓部である「ディープラーニング」を解剖しました。
- DLは「特徴量を自動で学ぶ」エース社員。
- 「ニューラルネットワーク」という脳を持ち、「深い層」で文脈や抽象概念を理解する。
- 私たちが使うのは「Transformer」という設計図で作られた「LLM」である。
- しかし「ハルシネーション」などの限界も持つ。
これで、S3(ML)とS4(DL)、つまりAIの「頭脳」の全貌が明らかになりました。 S3のML(インターン)は「支援ツール」であり、S4のDL(エース)は「共著者」です。
しかし、知識(What)だけではブログは稼げません。 次のS5(実践編)では、この「クセのあるインターン(ML)」と「暴走しがちなエース(DL)」を、私(運営者)がどのように「マネジメント」し、cosmic-note.com のような専門ブログでE-E-A-T(専門性・信頼性)のある記事を「戦略的(How)」に作り上げているのか。そのすべてを解説します。
【実践】ML/DL知識をAIブログ運営に活かす3つの戦略 (成功例: cosmic-note.com)
S1からS4まで、お疲れ様でした。 私たちは「AI」というスポーツの全体像(S2)を掴み、「ML=指示待ちのインターン」(S3)と「DL=自走するエース社員」(S4)という、AIの「頭脳」の仕組みを徹底的に解剖してきました。
S4の最後で、DL(エース)は「Transformer」という強力なエンジンを積みながらも、「ハルシシネーション」や「バイアス」といった「暴走」の危険をはらんでいることも確認しました。
知識(What)は揃いました。 S5は、この記事の「結論」であり、最も実用的な「実践編(How)」です。
この「クセのあるインターン(ML)」と「暴走しがちなエース(DL)」を、私(運営者)がどのように「マネジメント」し、Google AdSense審査やSEOで勝てる「E-E-A-T(経験・専門性・権威性・信頼性)」のある記事を戦略的に生み出しているのか。
S1(導入)でお約束した、私の運営する宇宙専門ブログ cosmic-note.com での具体的な「物語(経験)」を交えながら、明日からあなたのAIブログ運営を変える「3つの戦略」を公開します。
戦略1: 「適材適所」のツール選定(MLとDLの使い分け)
AIブログ運営者の最初の失敗は、「DL(エース社員)=ChatGPT」に、ML(インターン)の仕事までやらせようとすることです。
S4で学んだ通り、DLは「非構造化データ(文章、画像)」の生成・要約は得意ですが、S3のMLが得意とする「構造化データ(数値、表)」に基づく「予測」や「分類」は専門外です。
▼私の失敗談(Experience)
cosmic-note.com の運営初期、私はChatGPT(DL)にこう聞いていました。 「『ブラックホール 仕組み』というキーワードのSEO難易度を予測して」 ChatGPTは「SEO難易度は中程度です。なぜなら…」と、それらしい答えを生成しました。しかし、その「中程度」という数値に一切の根拠はありません。DLは「予測」しているのではなく、「予測しているかのような文章」を生成(ハルシネーション)しただけです。
▼AIブロガーの正しい戦略(Expertise)
私たちは「マネージャー」として、インターンとエースの仕事を明確に分けなければなりません。
- ML(インターン)に任せる仕事:
- 役割: 分析・予測・分類(S3の教師あり学習など)
- 具体例: SEOツールの「キーワード難易度」や「検索ボリューム」の予測。Googleアナリティクスの「読者セグメンテーション(仲間分け)」。AdSenseの「広告最適化」。
- 結論: 「数値」や「予測」が欲しい時は、専用のMLベースツール(SEOツールなど)を使います。
- DL(エース社員)に任せる仕事:
- 役割: 生成・要約・翻訳(S4のLLM)
- 具体例: 専門記事(
cosmic-note.com)の下書き作成。複雑な論文の要約。記事に合わせた画像の生成。 - 結論: 「0から1」のコンテンツ(文章、画像)を作る時に使います。
「SEO難易度をDLに聞く」のは、「エース社員に単純なデータ入力をさせる」のと同じくらい非効率な間違いなのです。
戦略2: E-E-A-Tを「プロンプト」で注入する(AIへの指示術)
S1で「AI丸投げではAdSenseに落ちる」と書きました。その理由は、AIが生成しただけの記事が、Googleの求めるE-E-A-T(特に「経験」と「専門性」)を欠いているからです。
S4でDL(エース)の「暴走(バイアス)」を知った私たちは、AIに「丸投げ」するのではなく、AIを「共著者として導く」必要があります。その「導き」こそが「プロンプト」です。
▼ cosmic-note.com での実践プロンプト(E-E-A-Tの注入)
私が cosmic-note.com で「クエーサー」についての記事をAI(DL)と共著する際、絶対に「クエーサーについて書いて」とは指示しません。それでは「ウィキペディアの劣化コピー」が出来上がるだけです。
私は「マネージャー」兼「ディレクター」として、E-E-A-Tの各要素をプロンプトで「注入」します。
- E(Expertise=専門性):
- 悪い指示: 「専門的に書いて」
- 良い指示: 「あなたは京都大学の宇宙物理学の博士課程を修了した研究者です(ペルソナ指定)。クエーサーの中心にある超大質量ブラックホールの活動メカニズムについて、高校生でも理解できるように比喩を用いて解説してください(筆者の専門性=分かりやすく翻訳する能力の注入)」
- E(Experience=経験):
- 悪い指示: 「あなたの体験談を書いて」(AIには経験がない)
- 良い指示: 「記事の冒頭に、『[ここに、筆者が初めてハッブル宇宙望遠鏡が捉えたクエーサーの画像を見た時の感動体験を挿入する]』という目印(プレースホルダー)を挿入してください」
- →(AIが目印を挿入)→ その部分を、私自身の「本物の言葉」で書き直します。 AIに「偽の経験」を書かせるのではなく、人間が「本物の経験」を埋める。これが「AIとの共著」です。
- A(Authoritativeness=権威性):
- 悪い指示: 「正しい情報を書いて」
- 良い指示: 「この記事で参照する情報源(ソース)は、NASAの公式発表、およびJAXA(宇宙航空研究開発機構)の最新の論文のみに限定してください(権威性の注入)」
- T(Trustworthiness=信頼性):
- 良い指示: 「記事の最後に、この記事がAI(Gemini 2.5 Pro)によって生成された下書きを基に、運営者(私)が全面的なファクトチェックと経験に基づく加筆修正を行ったことを明記する(透明性と信頼性の確保)」
この「E-E-A-T注入プロンプト」によって初めて、AI(DL)は「エース社員」として機能し、Googleにも読者にも評価される「専門記事」の土台を作ることができるのです。
いますぐ使える!E-E-A-T注入プロンプト [汎用テンプレート]
#役割
あなたは[ペルソナ(例:〇〇分野の専門家、経験豊富なジャーナリスト)]です。
#参照情報
この記事で参照する情報源は[権威ある情報源A(例:NASA公式サイト)]と[権威ある情報源B(例:JAXAの論文)]のみに限定してください。
#執筆指示
[ここに執筆したい内容(トピック、ターゲット読者、文体)]
#E-E-A-Tの組み込み
* 記事の冒頭には、[筆者の具体的な経験を挿入するためのプレースホルダー(例:私が初めて〇〇を体験した時の感動)]を挿入してください。
* 記事の最後には、[AIと人間による共著である旨の明記(透明性)]を挿入してください。
戦略3: 「ファクトチェック(人間)」を最終防衛ラインとする
最後の戦略であり、AIブログ運営者の「最も重要な義務」です。
S4で解説した通り、DL(エース社員)は「ハルシネーション(幻覚)」を起こし、平気で「嘘」をつきます。
AIブログ運営者の「信頼性(T)」は、この「嘘」をそのまま公開した瞬間にゼロになります。AI(DL)は「共著者」ですが、記事の「最終責任者」は、あなた(人間)です。
▼私の cosmic-note.com 運営ルール(Experience)
cosmic-note.com は専門性が高いため、一つの「嘘」が致命傷になります。AIが生成した原稿に対し、私は以下の「ファクトチェック」を自分に義務付けています。
- 「固有名詞」はすべて疑う:
AIが「超新星1987Aは…」と書いた場合、それが本当に「1987A」だったか、別の超新星と混同していないか、必ずNASAや専門機関のデータベースでクロスチェックします。 - 「数値・日付」はすべて疑う:
AIが「約138億年前の…」と書いた場合、その数値の「最新の出典」を確認します。科学的データは日々更新されるため、AIの学習データが古い可能性があるからです。 - 「情報源」を必ず確認する:
AIが「ある研究によると…」と書いた場合、その「ある研究」とは「誰の」「いつの」論文なのか、出典を明記させ、その論文が実在するか(ハルシネーションでないか)を確認します。
▼AIブログ運営者の「覚悟」(私の分析)
AIに丸投げして「1日100記事投稿!」といったAIブログ自動化戦略は、ハルシネーションを撒き散らす「スパムブログ」と何ら変わりません。
S3のML(インターン)でキーワードを「分析」し、S4のDL(エース)でE-E-A-Tプロンプトに基づいた「下書き」を作らせ、最後にS5の「人間(あなた)」が徹底的にファクトチェックと経験談の加筆を行い、「品質(E-E-A-T)」を担保する。
この「AIと人間の戦略的協業」(全自動執筆フローとは異なる)こそが、Google AdSense審査に合格し、SEOで長期的に生き残る、唯一の方法だと私は確信しています。
┌───────────────────┐
│ 1. 分析 (ML)
│ SEOツールで
│ キーワード分析・予測
└───────────────────┘
↓
┌───────────────────┐
│ 2. 起草 (DL)
│ AI (DL) が下書きと
│ プレースホルダー生成
│ (S5-2 E-E-A-T注入)
└───────────────────┘
↓
┌───────────────────┐
│ 3. 執筆 (人間)
│ 人間の「本物の物語」で
│ 「(E)経験」を埋める
└───────────────────┘
↓
┌───────────────────┐
│ 4. 監査 (人間)
│ ファクトチェック (S5-3)
│ (ハルシネーション排除)
└───────────────────┘
↓
┌───────────────────┐
│ 5. 公開
│ (T) 透明性の確保
│ (AI共著明記)
└───────────────────┘
まとめ: AIの「中身」を理解し、一歩先のAIブログ運営者になろう
AIブログの「頭脳」である「機械学習(ML)」と「ディープラーニング(DL)」の違いを巡る長い解説に、最後までお付き合いいただきありがとうございました。
私たちは、AIを「何でもできる魔法の箱」としてではなく、その「中身」を理解し、特性を活かす「強力な道具」として使いこなすための、確かな「解像度」を手に入れました。
この記事の核心を、私たちがS3からS4で使ってきた「物語」で再確認しましょう。
- 機械学習 (ML) =「指示待ちのインターン」
SEOツールのキーワード予測やAdSenseの広告最適化を担う、ブログ運営の強力な「支援ツール」でした。 - ディープラーニング (DL) =「自走するエース社員」
ChatGPTやGeminiのエンジンであり、記事の「共著者」となる存在でした。
しかし、この優秀なエース(DL)は、平気で「嘘(ハルシネーション)」をつき、学習データ次第で「暴走(バイアス)」します。
だからこそ、S5で解説した「人間(あなた)」の役割が、AIブログ運営の「すべて」を決めます。
AIを「マネージャー」として適材適所に使いこなし、E-E-A-T(特に「経験(E)」と「信頼性(T)」)をプロンプトで注入し、最終的な「ファクトチェック」の全責任を負う。
それこそが、AIの「中身」(AIとは何か)を理解した、一歩先のAIブログ運営者が実践すべき「稼ぐ」ための本質です。
▼次のステップ:この知識を「実践」に変える
今回の知識(What)を手に入れたあなたは、次はいよいよ「実践(How)」です。AIの「頭脳」を理解した今だからこそ、AIへの「指示(プロンプト)」の質が劇的に変わるはずです。
- S5で触れたE-E-A-T戦略とAdSense審査については、こちらの記事でさらに深く解説しています。
→ 参照:『AIブログは審査に通る? 「E-E-A-T」 で紐解くアドセンス合格完全ガイド』 - また、DL(エース社員)の能力を最大限に引き出すための具体的なプロンプト術は、こちらで全解剖しています。
→ 参照:『【失敗談あり】 AIブログ丸投げで大失敗した私が辿り着いた「プロ品質」 11工程ワークフロー全解剖』 - AIブログの成果を最大化する「プロンプト」の重要性については、こちらもご覧ください。
→ 参照:『AIブログの成果は「プロンプト」が9割だった』
AIを「使いこなす」運営者として、高品質なコンテンツを生み出していきましょう。





















この記事へのコメントはありません。