
AIブログ運営術に興味を持つあなたなら、一度はこう考えたことがあるはずです。ChatGPTやGeminiの登場以降、AIに記事を書せること自体は、もはや誰にでもできる簡単な作業になりました。
しかし、現実はどうでしょうか?
「AIが生成する記事の品質が低すぎて、使い物にならない」
「結局、修正作業に追われて、自分で書くより時間がかかっている」
「専門的な内容になると、途端に浅い情報やウソばかり吐き出す」
これは、AIブログ自動化に挑戦した多くの運営者がぶつかる「壁」です。
何を隠そう、この【AIブログ運営術】を運営している私自身も、最初はまったく同じ悩みを抱えていました。AIに指示(プロンプト)を出すものの、出力は不安定。まるで「機嫌の悪いアシスタント」を相手にしているようで、自動化どころか「AIの修正地獄」に陥っていたのです。
なぜ、AIの出力は安定しないのか。どうすれば、AIに「求める品質」の記事を、安定して書かせることができるのか。
試行錯誤の末、私はAIの品質を決定づける「たった一つの要素」に辿り着きました。
それが、この記事のテーマである「変数」です。
「プロンプトが9割」の本当の意味
以前の記事(AIブログの成果は「プロンプト」が9割だった)で、私は「AIブログの成果はプロンプトが9割」だとお伝えしました。これは事実です。
しかし、多くの初心者が「プロンプト」という言葉を、「AIに投げ込む魔法の呪文(命令文)」のように誤解しています。そして、「最強のプロンプト」さえ手に入れれば、すべてが解決すると思い込んでしまうのです。
ですが、考えてみてください。
もし、あなたがアシスタントに「最高のレシピ(プロンプト)」を渡したとしても、「今日の具材(記事テーマ)」や「食べる人(読者)」、「調味料(参考情報)」を伝えなければ、まともな料理は出来上がるでしょうか?
AIブログにおける「変数」とは、まさにこの「毎回変わる情報」を、AIの「思考」に正確に組み込むための仕組みです。
もう少し具体的に言えば、「変数」とは、プロンプトという「指示書のテンプレート」に空けられた「穴」のこと。
{topic}(今回の記事テーマ){target_reader}(想定読者){pre_search}(事前に集めた専門情報)
私たちは、この「穴(変数)」に適切な情報を流し込むことで初めて、AIの思考をコントロールし、望むアウトプットを引き出すことができるのです。
逆に言えば、AIの品質が安定しない最大の原因は、この「変数」の設計が曖昧だからに他なりません。変数が曖昧な指示は、AIにとって「何を、誰に、どのレベルで書けばいいか分からない」という混乱の元。結果として、当たり障りのない、誰にも刺さらない記事が量産されてしまうのです。
証拠:宇宙物理学ブログ(専門ジャンル)での成功
「本当にAIに専門的な記事が書けるのか?」
「AIが書いた記事が、Googleに評価されるのか?」
当然の疑問だと思います。そこで、私がこの「変数管理」を徹底したAI執筆フローを用いて運営している、もう一つのサイトの事例をご紹介します。
- 運営サイト:
https://cosmic-note.com/ - ジャンル: 宇宙と物理学(「『相対性理論』記事で実証!」や「量子力学」などを扱う、非常に専門性が高く、競合が少ないニッチジャンル)
このジャンルは、AIが最も苦手とする「正確性」と「専門性(Googleがサイトの品質を評価するための基準)」が求められる分野です。
このサイトの運営で、私はAIに記事を「丸投げ」するのではなく、AIの「思考」を制御する「変数」を徹底的に設計しました。
{topic}(例:「シュレディンガーの猫とは何か?」){pre_search}(信頼できる物理学の論文や専門サイトの情報){outline}(記事全体の論理構成){previous_sections}(直前までの執筆内容)
これらの変数をAIワークフローに組み込み、AIに「思考のレール」を敷いた上で執筆させた結果、どうなったか。
- Googleのインデックス登録率100%を達成(技術的SEOのクリア)
- Googleアドセンス審査に一発通過(コンテンツ品質のクリア)
以下の画像が、そのインデックス状況を示す実際のGoogleサーチコンソールの画面です。専門的な内容でもAIを活用して品質を担保すれば、Googleは正当に評価してくれます。
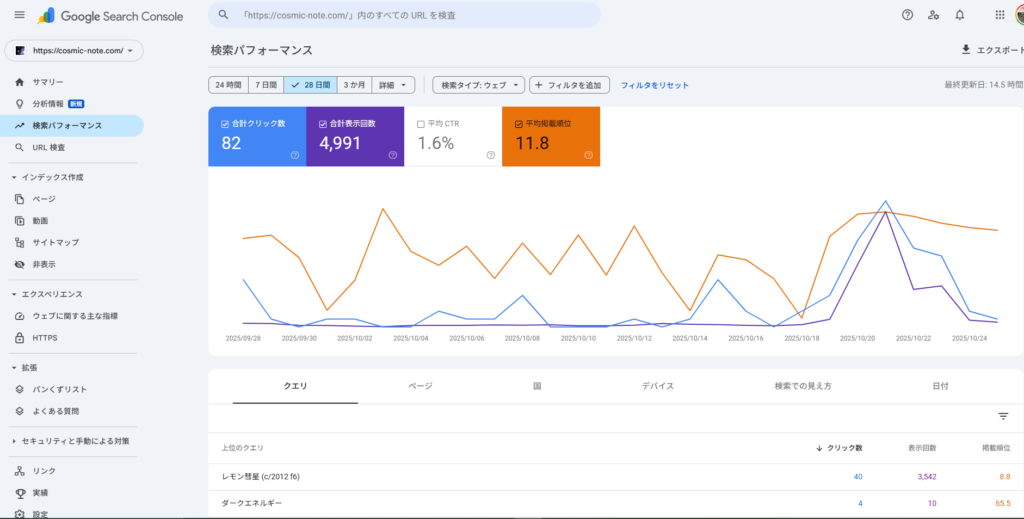
この事例は、本記事で解説する「変数管理」の手法が、単なる机上の空論ではないこと。そして、AIは専門ジャンルにおいてもGoogleから適切に評価され、技術的なSEOとコンテンツ品質の両面で成功可能であることを示しています。
AIは「道具」です。そして「変数」は、その道具(AI)に最高の仕事をさせるための「指示書(レシピ)の核」です。
この記事では、AIブログ自動化のまさに「心臓部」である、この「変数」の全貌を徹底的に解剖します。
あなたがAIブログの「修正地獄」から抜け出し、「自動化」の本当の果実を手にするための、実践的な技術をお伝えします。
【全体設計編】AI執筆システムの「司令塔」。全体を司る最重要変数(`${topic}`, `structure`, `pre_search`)
S1(導入)では、AIブログ自動化の品質は「変数」で決まること、そしてその証拠として、専門ジャンル(宇宙物理学)のブログでGoogleに評価された(インデックス率100%・アドセンス通過)事例をお見せしました。
読者の皆さんは今、「変数が重要なのは分かった。では、具体的にどんな変数があり、どう使えばいいのか?」という疑問でいっぱいだと思います。
AIブログの自動執筆フローは、家づくりと非常によく似ています。
いきなりAIに「記事を書いて(家を建てて)」と丸投げするのは、「設計図も材料も渡さずに、最高の家を建てろ」と無茶振りするようなものです。結果は、S1でお話しした「AIの修正地獄」です。
品質の高い記事を「自動で」生み出すには、まず強固な「全体設計」が必要です。
このセクションでは、AI執筆システム全体の「司令塔」として機能する、最も重要な3つの「設計変数」について、私が実際にcosmic-note.comや当ブログで使っている実践的な視点から徹底解説します。
1. `${topic}`:AIの思考を定める「北極星」
AI執筆フローの「すべて」の始まり、それが`${topic}`(トピック)変数です。
- これは何か?: その記事で「何を伝えるか」を定義する、記事の核となるテーマです。
- なぜ重要か?: この`${topic}`(北極星)を起点に、まずAIの「設計図」である`structure`(構成案)が生成されます。そして次に、その`structure`(設計図)に基づいて、記事の「材料」となる`pre_search`(事前リサーチ)が収集されるのです。この「司令塔」から「設計図」、そして「材料」へと続く情報の連鎖こそが、AI執筆フローの土台となります。
この変数の連鎖的な流れ(依存関係)を視覚化すると、以下のようになります。

初心者がつまずく「ダメな`${topic}`」
私がAI自動化の初期に失敗していた最大の原因が、この`${topic}`の定義が曖昧だったことです。
多くの人が、`${topic}`を単なる「検索キーワード」と勘違いしています。
- ダメな`${topic}`の例:
AIブログプロンプト宇宙
これでは、AIは何を書けばいいか分かりません。「AIブログについて、何を知りたいの? メリット? 危険性? 始め方?」とAIが混乱し、結果として浅く、総花的な、誰にも刺さらない記事が出来上がります。
運営者の視点:`${topic}`は「読者の悩み」を言語化したもの
高品質な記事を生み出す`${topic}`とは、「読者が解決したい悩み(検索意図)」を、AIが理解できるように具体的に言語化したものです。
- 良い`${topic}`の例:
- (ダメな例:
AIブログ) - → 良い例:
AIを使ってブログ記事を自動化したいが、品質が低く修正地獄に陥っている運営者向けに、その原因と解決策(変数管理)を解説する
- (ダメな例:
- 良い`${topic}`の例(この記事の例):
AIブログ自動化のプロンプトで使う「変数」について、その具体的な役割と使い方を、初心者にも分かりやすく体系的に解説する
ここまで具体化して初めて、AIは「なるほど、今回のゴールは『変数』の解説なんだな」と理解し、的確な構成案やリサーチを開始できるのです。
2. `structure`:AIの暴走を防ぐ「思考のレール」
`${topic}`(北極星)が決まったら、次に行うのは「1. ブログ構成プロンプト」を使い、AIに記事全体の「設計図」を作らせることです。
このAIが生成した「設計図(JSON形式)」こそが、2つ目の司令塔変数、`structure`(構成案)です。
- これは何か?: 記事全体のセクション構成、各セクションのタイトル、そこで伝えるべき核心メッセージ(概要)を定義した、記事の「骨格」です。
- なぜ重要か?: これがAIの「思考のレール」となり、記事の論理破綻(話が逸れる、同じことを繰り返す)を防ぐ生命線となるからです。
運営者の視点(E-E-A-T: Experience):AIは「長文」が書けない
AI自動化で最もやってはいけないのが、AIに「記事全体を一度に書せる」ことです。
AI(大規模言語モデル)は、その仕組み上「直前の文脈」にしか集中できません。5,000文字の記事を書かせようとすると、後半では「前半で何を書いたか」を忘れ、平気で矛盾したことを書いたり、結論がズレたりします。
これを防ぐ唯一の方法が、「プロンプトチェーン(タスクの分割)」です。
当ブログのAI執筆フロー(添付ファイル参照)では、記事全体をS1〜S5の「セクションごと」に分割し、AIに「別々のタスク」として執筆させています。
その際、すべてのセクション執筆プロンプトに、この`structure`変数を「共通の設計図」として渡すのです。
▼ AIへの指示(イメージ)
「今からS3(執筆サイクル編)を書くぞ。記事全体の設計図(`structure`)はこれだ。君の役割(S3の概要)は『AIの短期記憶を繋ぐ変数を解説すること』だ。分かったな?」
このように`structure`変数を使い回すことで、AIは「今、自分は全体のどの部分を、どんな役割で書いているのか」を常に認識し続けられます。これが、AIの思考をレールに乗せ、一貫性を保つための核心技術です。
3. `pre_search`:専門性を注入する「外部知識」
設計図(`structure`)ができたら、次は「材料」の調達です。AIは「それらしい文章」を作る天才ですが、「最新の専門知識」を持っているわけではありません。
そこで登場するのが、3つ目の司令塔変数、`pre_search`(事前リサーチ)です。
- これは何か?: 記事の専門性や信頼性を担保するために、AI自身が(または人間が)収集した「信頼できる外部情報」の束です。
- なぜ重要か?: AIの最大の弱点である「ハルシネーション(嘘)を防ぎ」、記事にE-E-A-T(専門性・権威性・信頼性)を注入するためです。
運営者の視点(E-E-A-T: Expertise/Trust)
S1で紹介したcosmic-note.com(宇宙物理学ブログ)が、なぜGoogleに評価されたのか。その最大の秘訣が、この`pre_search`変数の徹底的な活用です。
「相対性理論」の記事を書く際、私はAIに「君の知っている相対性理論を書いて」とは絶対に指示しません。
そうではなく、まず「2. リサーチ」プロンプトを使い、信頼できる情報源(大学の論文、物理学の専門サイト、権威ある書籍)をAIに検索させ、その結果を`pre_search`変数に格納させます。
(※厳密には、`structure`(設計図)で決まったセクション構成に基づいて、必要なリサーチを行わせます)
そして、執筆プロンプトでこう指示するのです。
▼ AIへの指示(イメージ)
「`{topic}`(相対性理論)について書くぞ。君の内部知識は一切使うな。この`{pre_search}`(信頼できる外部情報)だけを情報源として、設計図(`structure`)に従って記事を書きなさい」
これが、AIブログで専門性と信頼性を担保する唯一の方法です。
AIを「全知全能の神」として扱うのではなく、「優秀だが知識のないアシスタント」として扱い、必要な「知識(`pre_search`)」は私たちが変数として与える。
この`${topic}`(北極星)、`structure`(設計図)、`pre_search`(外部知識)という3つの「司令塔」変数を執筆フローの「最初」に確定させること。
これが、AIブログ自動化の品質を「システムレベル」で決定づける、最も重要なステップなのです。
【執筆サイクル編】AIの「短期記憶」を繋ぐ。高品質な本文を生成させる変数群
S2(全体設計編)では、AIブログの「設計図」にあたる司令塔変数(`${topic}`, `structure`, `pre_search`)を解説しました。
そして、「AIは長文が書けないため、記事をセクションごとに分割して執筆させる(プロンプトチェーン)のが必須技術だ」とお伝えしました。
ここで、聡明なあなたはこう思うはずです。
「セクションごとに分割して書かせたら、S1とS3で話が矛盾したり、S2とS4で同じ内容を繰り返したりしないか?」
「分割したセクションを、どうやって論理的に一貫性のある『1本の記事』として繋げるんだ?」
その通りです。これこそが、AI自動化における「第二の壁」です。
このセクションでは、分割されたAIのタスク(セクション執筆)を論理的に繋ぎ合わせ、AIに「文脈」という名の記憶を持たせるための「執筆サイクル変数」について、その核心を解説します。
AIの「短期記憶」問題という絶望
まず、AI(大規模言語モデル)の根本的な特性を、運営者である私たちは理解しなくてはなりません。
それは、AIは「超高性能なオウム」であり、基本的に「直前の文脈」しか覚えていられないということです。
私がAI自動化で失敗していた頃、S2で解説した`structure`(設計図)だけをAIに渡し、セクションごとに執筆させていました。
- タスク1: 「S1(導入)を書いて」(AI執筆 → 完成)
- タスク2: 「S2(全体設計編)を書いて」(AI執筆 → 完成)
- タスク3: 「S3(執筆サイクル編)を書いて」(AI執筆 → 完成)
そして、完成したS1, S2, S3を最後に手作業(コピペ)で結合して、「記事の完成だ!」と喜んでいました。
しかし、出来上がった記事を読んで愕然とします。
- S1の導入で「AIブログは簡単だ」と書いたのに、S3で「AIブログは非常に難しい」と矛盾した主張をしている。
- S2で解説した「`${topic}`変数の重要性」を、S3でまたゼロから解説し始めている(内容の完全な重複)。
なぜこんなことが起きるのか?
理由は単純です。AIがS3を書いている時、AIは「S1とS2で何を書いたか」を一切覚えていないからです。
AIにとって、タスク1(S1執筆)とタスク3(S3執筆)は、完全に「別世界」の出来事。これはまるで、「記憶が1日しかもたないアシスタント」に、毎日ゼロから同じ背景を説明して記事の続きを書かせるようなものです。これでは「自動化」ではなく「徒労」です。
生命線:`${previous_sections}`(直前までの本文)
この「AIの短期記憶」問題を解決し、AIに「記事全体の文脈」という名の長期記憶を与える唯一にして最強の変数が、`${previous_sections}`(直前までの執筆済み本文)です。
- これは何か?: 現在のセクションを執筆する「直前」までに完成した、すべての本文テキスト。
- なぜ重要か?: これをAIに渡すことで、AIは「(S1でこんな導入をし、S2でこんな解説をした)続きとして、S3を書けばいいんだな」と文脈を理解できる。これが論理破綻と重複を防ぐ生命線です。
。
この「記憶が連鎖していく様子」を視覚化すると、以下の図のようになります。

▼ AI執筆フロー(フェーズ2)のイメージ
- S1執筆時:
previous_sections = ""(空っぽ)content_S1 = run_prompt("3. 執筆", previous_sections=...) - S2執筆時:
previous_sections = content_S1(S1の本文が入る)content_S2 = run_prompt("3. 執筆", previous_sections=...) - S3執筆時(今ココ):
previous_sections = content_S1 + content_S2(S1とS2の本文が入る)content_S3 = run_prompt("3. 執筆", previous_sections=...) - S4執筆時:
previous_sections = content_S1 + content_S2 + content_S3
… (以下、雪だるま式に増えていく)
(※実際の運用では、AIが一度に読み込める文字数(コンテキストウィンドウ)に限界があるため、previous_sectionsが長くなりすぎる場合は、直近の数セクションの本文や要約を渡す、といった工夫が必要になる場合もあります。しかし、「直前の文脈(記憶)を渡す」という根本的な考え方は同じです)
詳しくはこちら
"""完成までの流れを正確に整理すると、以下のようになります。
# ---
# フェーズ1:準備(最初の一回だけ)
# ---
# 1. 記事全体の構成(設計図)を作成
structure = run_prompt(""""1. ブログ構成プロンプト"""", topic=""""記事の品質検査プロンプト"""")
# 2. 記事全体で利用する事前リサーチを実施
pre_search = run_prompt(""""2. リサーチ"""", structure=structure)
# ---
# フェーズ2:執筆サイクル(セクションごとに繰り返す)
# ---
# ▼ S1(セクション1)の執筆サイクル
# 3. S1の本文を執筆
content_S1 = run_prompt(""""3. セクションのライティング"""",
structure=structure,
section_title=""""S1のタイトル"""",
section_summary=""""S1の概要"""",
previous_sections="""""""", # S1なので空
pre_search=pre_search)
# 4. S1をレビュー
review_S1 = run_prompt(""""4. セクションレビュー用"""",
outline=structure,
section_title=""""S1のタイトル"""",
content=content_S1)
# 7. S1を修正
content_S1_final = run_prompt(""""7. 修正用プロンプト(セクション用)"""",
content=content_S1,
review=review_S1)
# ▼ S2(セクション2)の執筆サイクル
# 3. S2の本文を執筆
content_S2 = run_prompt(""""3. セクションのライティング"""",
structure=structure,
section_title=""""S2のタイトル"""",
section_summary=""""S2の概要"""",
previous_sections=content_S1_final, # S1の完成版を渡す
pre_search=pre_search)
# 4. S2をレビュー
review_S2 = run_prompt(""""4. セクションレビュー用"""",
outline=structure,
section_title=""""S2のタイトル"""",
content=content_S2)
# 7. S2を修正
content_S2_final = run_prompt(""""7. 修正用プロンプト(セクション用)"""",
content=content_S2,
review=review_S2)
# ▼ S3〜S5も同様に繰り返す...
# ... (S3, S4, S5 の執筆・レビュー・修正) ...
# 例:S3執筆時
# previous_sections = content_S1_final + content_S2_final
# 例:S5執筆時
# previous_sections = content_S1_final + ... + content_S4_final
content_S3_final = """"...""""
content_S4_final = """"...""""
content_S5_final = """"..."""" # S5まで完了したとする
# ---
# フェーズ3:全体仕上げ(全セクション完了後)
# ---
# 全セクションの完成本文を結合
content_all = content_S1_final +
content_S2_final +
content_S3_final +
content_S4_final +
content_S5_final
# 5. 記事全体をレビュー
review_all = run_prompt(""""5. レビュー全体用"""",
structure=structure,
content=content_all)
# 6. (オプション)専門レビュー
review_expert = run_prompt(""""6. 専門レビュー"""",
structure=structure,
content=content_all)
# 7. 記事全体を最終修正
content_final = run_prompt(""""7. 修正用プロンプト(全体用)"""",
structure=structure,
content=content_all,
review=review_all + review_expert)
# 8. または 10. 最終的な形式に出力
markdown_output = run_prompt(""""8. マークダウン"""",
content=content_final)
# html_output = run_prompt(""""10. HTML化"""",
# content=content_final)
echo """"--- 記事制作完了 ---""""
echo markdown_output"""このように、執筆サイクルが進むたびにprevious_sections変数が「成長」していく仕組みこそが、AIに「記憶」を持たせるカラクリです。
運営者の視点(E-E-A-T: Expertise):AIへの「制約」として機能する
このprevious_sections変数の真価は、単なる「記憶」の提供に留まりません。
AIに対する「強力な制約(ネガティブ・インストラクション)」として機能します。
執筆プロンプト(3. セクションのライティング)の中で、私はAIにこう指示しています。
▼ AIへの指示(イメージ)
「…(前略)… これから`${section_title}`(S3)を執筆してください。
ただし、以下の`${previous_sections}`(S1とS2の本文)で既に解説済みの内容と、絶対に重複しないように注意してください。」
この一文(変数を使った制約)があるおかげで、AIはS3を書く際に「あ、この話はS2で書いたから、S3では別の切り口で書こう」と自己制御するようになります。
これが、AIによる「内容の重複」を防ぎ、各セクションが固有の価値を持つ、論理的な記事を自動生成させるための核心技術です。
執筆サイクルを回す「その他の変数」たち
previous_sectionsが「記憶」の役割なら、執筆サイクル(セクションごとの執筆タスク)を正確に回すためには、他にもAIに渡すべき「作業指示書」が必要です。
これらは主に、S2で作った「司令塔」変数(`structure`や`pre_search`)を、執筆タスク用に「切り出し」たり「再利用」したりするものです。
section_title/section_summary- 役割: AIの「焦点(スコープ)」を絞る。
- 解説: S2で作った全体設計図(`structure`)から、今書くべきセクションの「タイトル」と「概要(核心メッセージ)」だけを抜き出した変数です。「今は記事全体のうち、ココだけを、このメッセージを伝えるために書け」と、AIのタスクを限定します。
structure(再利用)- 役割: 常に「全体の地図」を見せる。
- 解説: S2の司令塔変数ですが、セクション執筆時(S3)にも「毎回」渡します。「君は今、家全体(`structure`)のうち、『リビング(S3)』を作っている。前後に『玄関(S1)』と『キッチン(S4)』があることを忘れるなよ」と、AIに全体像を常にリマインドさせます。
pre_search(再利用)- 役割: 使える「材料」を限定する。
- 解説: S2で集めた「外部知識(材料)」も毎回渡します。「リビング(S3)を作るために使っていい材料は、この`pre_search`(事前リサーチ)だけだ。君の勝手な知識(ハルシネーション)で変な材料を使うなよ」と釘を刺すためです。
S2の「司令塔」変数が「家全体の設計図と全材料」なら、S3の「執筆サイクル」変数は、「各部屋の内装工事を行うための、個別の指示書と記憶(直前までの作業記録)」と言えます。
このサイクル変数を正確に管理・運用することで、AIは初めて「記憶を持った職人」として、論理一貫性のある高品質な記事をセクションごとに生み出せるようになるのです。
【品質管理編】AIに「自己修正」させる魔法の変数(`content`, `review`, `outline`)
S2(全体設計編)で「設計図」を作り、S3(執筆サイクル編)で「記憶」を持たせ、AIはついにセクションの「初稿」を書き上げました。
さて、AI自動化に挑戦した多くの初心者が、S1でお話しした「AIの修正地獄」に陥る、運命の分岐点がここです。
AIが書き上げた初稿(`${content}`)を見て、あなたはどうしますか?
- Aさん(修正地獄): 「うーん、悪くないけど、ここの言い回しが変だな…」と、自分で直接テキストを修正し始める。
- Bさん(自動化成功): 「OK、AI。今書いたその文章(`${content}`)と、元の設計図(`${outline}`)を見比べて、自分でレビュー(`${review}`)して改善案を出せ」と指示を出す。
Aさんは、AIを「ライター」として使い、自分は「編集者兼修正者」として働いています。これでは、記事が増えるたびにAさんの作業時間は増え、永遠に自動化は完成しません。
Bさんは、AIを「ライター」として使った後、AIを「編集者」としても利用し、AI自身に「自己修正」させています。
この【AIブログ運営術】(およびcosmic-note.com)の品質と効率を支える核心技術が、Bさんの手法、すなわちAIによる「セルフリファイン(自己修正)」サイクルです。
このセクションでは、AIを単なる執筆者から「優秀な編集者」へと変貌させる、品質管理(QA)のための変数群を解説します。
AIの「初稿」は「ドラフト」に過ぎない
まず、私たちが持つべき最も重要なマインドセット(心構え)は、「AIが3. 執筆プロンプトで生成したアウトプットは、決定稿ではなく、単なる『ドラフト(たたき台)』である」と認識することです。
この「ドラフト」の品質を「完成品」に引き上げるプロセスこそが、品質管理(QA)フェーズです。
このフェーズで活躍する変数は、以下の3つです。
- `${content}` (AIの初稿): S3で執筆された「ドラフト(たたき台)」。
- `${outline}` (設計図): S2で作った「記事全体の構成案(`structure`と同じ)」。
- `${review}` (AIによるレビュー結果): AIが「ドラフト」と「設計図」を比較して生成した「改善指示書」。
「セルフリファイン」サイクルの仕組み
当ブログのAI執筆フロー(プロンプト使用手順 - シート1.csv)では、1つのセクションを完成させるために、AIは「執筆」→「レビュー」→「修正」という3つのステップ(プロンプト)を踏みます。
▼ AI品質管理(QA)サイクル(フェーズ2)
- 執筆 (Prompt 3)
- AIが初稿(ドラフト)を執筆する。
- 出力: `${content}`
- レビュー (Prompt 4)
- AIが「編集者」役に変身する。
- 入力: `${content}`(さっき書いたドラフト)と `${outline}`(元の設計図)、そして `${previous_sections}`(S3で解説した「記憶」)
- 指示: 「設計図(`outline`)の指示(`section_summary`)を、ドラフト(`content`)は100%満たしているか?論理は破綻していないか?厳しくレビューせよ」
- 出力: `${review}`(AIによる自己レビュー結果)
- 修正 (Prompt 7)
- AIが「修正者」役に変身する。
- 入力: `${content}`(ドラフト)と `${review}`(たった今生成したレビュー結果)
- 指示: 「このドラフト(`content`)を、このレビュー(`review`)の指示に完全に従って修正し、決定稿(`content_final`)を生成せよ」
- 出力: `content_final`(セクションの完成本文)
このサイクルを、AIが全自動で実行するのです。
なぜこのサイクルがE-E-A-T(専門性)に効くのか
この「AIによる自己レビュー」の仕組みは、特にcosmic-note.com(宇宙物理学)のような専門ジャンルで絶大な威力を発揮します。
なぜなら、AIは「編集者」役として、人間では見落としがちな「AI自身の弱点」を客観的にチェックできるからです。
「4. セクションレビュー用」プロンプト(添付ファイル参照)には、以下のような指示(E-E-A-Tを担保する指示)が組み込まれています。
▼ AI(編集者役)への指示(イメージ)
- ハルシネーション(嘘)の検知:
「ドラフト(`content`)は、提供された`pre_search`(外部知識)の情報源だけに基づいていますか? 勝手な知識で作った情報(ハルシネーション)はありませんか?」 - 設計図との整合性:
「ドラフト(`content`)は、`outline`(設計図)で指示された核心メッセージ(`section_summary`)から逸脱していませんか?」 - 論理破綻の検知:
「ドラフト(`content`)は、`previous_sections`(前のセクション)の内容と矛盾したり、重複したりしていませんか?」
人間がAIの「嘘」や「論理破綻」をゼロから探すのは、膨大な時間がかかる「修正地獄」です。
しかし、この仕組みを使えば、AI自身に「自分の嘘」や「論理破綻」を(ある程度)検知させ、レビュー(`${review}`)として出力させ、さらに「自己修正」までさせることが可能になります。
AIに「書かせる」だけでは三流です。
AIに「書かせた後、レビューさせ、修正させる」。
S2の「司令塔」、S3の「記憶」に、このS4の「品質管理サイクル」が加わることで、AI執筆システムは初めて「信頼できる自動化」のレベルに到達するのです。
まとめ:変数を制する者がAIブログを制す。今日から始める「変数管理術」
AIブログ自動化の「心臓部」である変数について、その全貌を解説してきました。
S1の導入で、私は「AIの修正地獄」に陥っていた過去の失敗談と、cosmic-note.com(宇宙物理学)という専門ジャンルでGoogleに評価された(インデックス率100%)成功事例をお話ししました。
あの「修正地獄」から私を救い出し、専門ブログの成功を支えたものこそ、今回徹底解説した「変数」を軸にしたAI執筆システムです。
AIブログの自動化とは、「魔法のプロンプト(呪文)」を一つ見つける作業ではありません。
それは、AIの「思考」を正確にコントロールする「システム」を構築する作業です。
そして、そのシステムの「血液」であり「制御装置」の役割を果たすのが、この記事で解説した「変数」なのです。
- S2【全体設計編】: `${topic}`(北極星)、`structure`(設計図)、`pre_search`(外部知識)という「司令塔」変数で、AIの思考のレールを敷きました。
- S3【執筆サイクル編】: `${previous_sections}`(記憶)という変数で、AIの短期記憶を繋ぎとめ、論理破綻と重複を防ぎました。
- S4【品質管理編】: `${content}`と`${review}`を使い、AIに「自己修正」させるサイクル(セルフリファイン)を組み込み、品質を担保しました。
このS2からS4までの流れ、すなわちAI執筆システムの全体像を視覚化したものが、以下の図です。
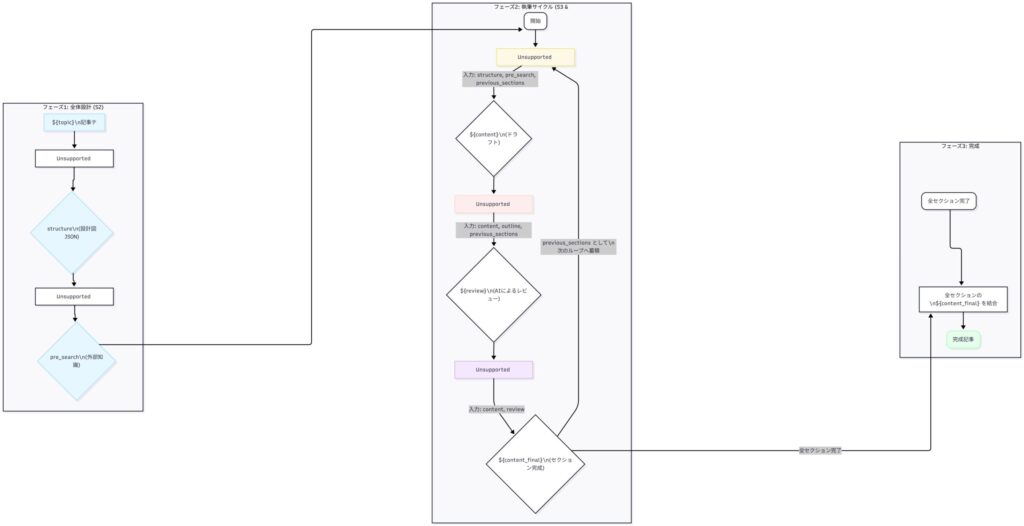
このシステムを運用する「管理者」こそが、S4で例えた「Aさん(修正地獄)」と「Bさん(自動化成功)」の分岐点を思い出してください。
AIを「機嫌の悪いアシスタント」として扱い、出力のたびに「修正者」として疲弊するAさんの道。
AIを「仕組みで動くシステム」として捉え、「管理者」としてAIに働いてもらうBさんの道。
この記事を読み終えた今、あなたに最初に行ってほしいアクションは、Bさんへの第一歩です。
それは、「最強のプロンプト」を探すのを、今日でやめることです。
代わりに、今あなたが使っている(あるいは使おうとしている)プロンプトを取り出し、そこに「変数として差し込むべき『穴({})』はどこか?」を自問してみてください。
- 「毎回、記事ごとに変わる情報は何か?」(それは`${topic}`や`${target_reader}`かもしれません)
- 「AIに事前に与えるべき専門知識は何か?」(それは`${pre_search}`かもしれません)
- 「AIに絶対に忘れてほしくない文脈は何か?」(それは`${previous_sections}`かもしれません)
変数を意識的に設計し、管理し、AIの思考をコントロールする。
変数を制する者が、AIブログを制します。
今日からあなたも「AIの修正者」を卒業し、「AIの管理者」として、本当の自動化への一歩を踏み出しましょう。




















この記事へのコメントはありません。